前几天其实一直在学习关于linux的内容和kvm虚拟化的知识。今天有时间来回顾一下集合相关的知识,接下来我将带大家一起来回顾一起集合关联的知识。
不要辜负自己花费时间做的事情,只有用心才能得到真心的回报!
关于java集合框架的知识:大致可分为Set、List和Map三种体系,其中Set代表无序、不可重复的集合;List代表有序、重复的集合;而Map则代表具有映射关系的集合。Java 5之后,增加了Queue体系集合,代表一种队列集合实现。
Java集合框架主要由Collection和Map两个根接口及其子接口、实现类组成。
集合类划分为两个大的部分:一种是可以按照一定顺序进行迭代访问的集合类;一种是通过名值对的映射建立关系进行访问的集合类
一、Collection接口概述
1.1、collection接口概述
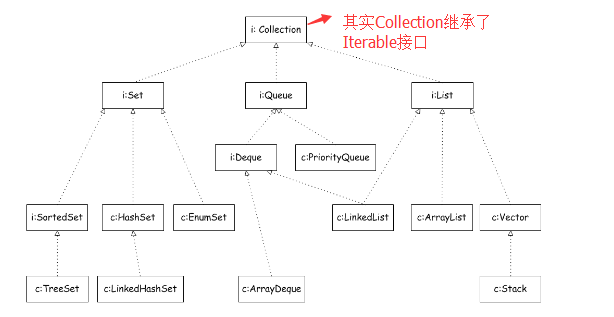
Collection接口是所有后续集合类型的一个公共抽象定义。它本身没有一个直接的实现,更多的是各种不同的集合类型在它的基础上继承了更多特殊的特性并做了一个实现。
Collection接口里主要定义了一些作为集合类型比较通用的方法,比如说size, isEmpty, add, remove等。作为集合类型比较通用的一个定义,它主要用在一些需要比较高级别抽象的地方。比如说我们需要可以对所有集合类型进行通用操作。
1.2、Collection接口定义的方法
(1)增加、add(E e) - 返回值为boolean(是否添加成功)。 (2)清除、clear() - 除去此数组的所有操作。 (3)是否包含某一元素、contains(Object o) - 如果包含返回为true(可以用于进行if判断),如果集合里边的元素为自定义 类的话需要重写自定类的equals方法(contains方法就是基于equals实现的)否则比较的是地址。 (4)比较此collection与指定对象是否相等、equals(Object o) - 返回值为boolean(true为相等)。 (5)此collection是否包含某元素、isEmpty() - 返回值为boolean(true为不包含)。 (6)获取此collection的迭代器、iterator() - 用于遍历集合(此迭代器只能遍历集合,不能对集合进行修改,否则会报并发 修改异常-ConcurrentModificationException)。 (7)删除指定元素、remove(Object o) - 返回值为boolean(true表示删除成功)。 (8)返回元素数(集合的长度)、size() - 返回值为int(集合中元素的个数)。 (9)返回此集合中所有元素的数组、toArray() - 返回值是一个数组。
二、Collection的子接口概述
2.1、set接口
在常用的集合类型中,HashSet, TreeSet等具体的实现往往不一样。比如说HashSet本身的实现是引用了HashMap作为内部的元素。如果我们仔细检查他们的结构实现,会发现有的类型我们也可以通过foreach的循环来遍历。
这是因为他们有的在实现Set定义接口的范围同时也继承了实现Collection接口的部分。可以说是两者兼有之。
在上面这些集合类型中,基于Hash表实现的主要有HashSet, LinkedHashSet。基于红黑树实现的有TreeSet.
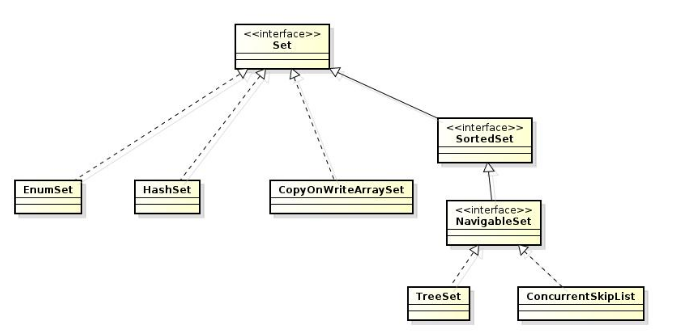
特点:无顺序,不可重复
1)HashSet
不能保证元素的排列顺序,加入的元素要特别注意hashCode()方法的实现。
HashSet不是同步的,多线程访问同一步HashSet对象时,需要手工同步
集合元素值可以是null。
2)LinkedHashSet
LinkedHashSet类也是根据元素的hashCode值来决定元素的存储位置,但它同时使用链表维护元素的次序。与HashSet相比,特点:
对集合迭代时,按增加顺序返回元素。
性能略低于HashSet,因为需要维护元素的插入顺序。但迭代访问元素时会有好性能,因为它采用链表维护内部顺序。
3)TreeSet
TreeSet类是SortedSet接口的实现类。因为需要排序,所以性能肯定差于HashSet。
4)EnumSet类
专为枚举类设计的集合类,EnumSet中的所有元素都必须是指定枚举类型的枚举值
2.2、List接口
List类型的数据结构算是我们平时接触最多而且看起来最简单的数据结构类型。最常用的两种是ArrayList和LinkedList,也就是我们常说的线性表和链表。
1)LinkedList类
内部使用链表的形式来存储数据,在增加和删除数据上面性能更好
它实现了List接口和Deque接口,说明它具有两边接口的特性,因此它可以当作一个双端队列来用,也可以当作栈来用,并且它是以链表的形式来实现的,所以查询性能差,但是增加和删除操作性能高。
2)ArrayList类
内部使用数组来存储数据,也就相当于数据结构的顺序表存储,在查询数据上面性能好,
3)Vertor类
跟ArrayList相比,它是线程安全的,而ArrayList是线程不安全的,
4)Stack类继承Vertor类
看名字,其实就是方便模拟“栈”这种数据结构
2.3、Queue
用于模拟队列这种数据结构,然后该接口中声明了一些基本操作的方法。例如:add、offer、remove等

1)PriorityQueue类
PriorityQueue保存队列元素的顺序并不是按照加入队列的顺序,而是按队列元素的大小重新排序
2)Deque接口
Deque代表一个双端队列,可以当作一个双端队列使用,也可以当作“栈”来使用,因为它包含出栈pop()与入栈push()方法。
3)ArrayDeque类为Deque的实现类
也就是实现了Deque接口中定义的方法,解释跟deque差不多
2.4、各种线性表中选择策略
数组:是以一段连续内存保存数据的;随机访问是最快的,但不支持插入、删除、迭代等操作。
ArrayList与ArrayDeque:以数组实现;随机访问速度还行,插入、删除、迭代操作速度一般;线程不安全。
Vector:以数组实现;随机访问速度一般,插入、删除、迭代速度不太好;线程安全的。
LinkedList:以链表实现;随机访问速度不太好,插入、删除、迭代速度非常快。
三、Map集合框架概述
Map接口:定义一些基本的操作,例如put(key,value), containKey(Object key)等一系列操作。
使用key、value键值对的形式进行访问的集合类
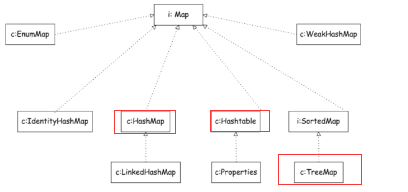
3.1、Map接口概述
1)HashMap类和Hashtable类对比,
一般使用HashMap,因为Hashtable类是很古老的,据查都不建议用。平常我们也是用HashMap
HashMap类是线程不安全的,而Hashtable是线程安全的
HashMap类可以使用null作为key和value,而Hashtable不可以
2)Properties类继承Hashtable类
增加了额外的一些方法,例如:load(InputStream inStream)从属性文件加载key-value等方法。
可以将key-value用xml文件的格式保存,可能就是跟xml文件打一些交道
3)LinkedHashMap类继承HashMap类
LinkedHashMap从HashMap类继承而来。以链表来维护内部顺序。很多方面跟LinkedHashSet类似。LinkedHashMap它可以记住key-value对的添加时的顺序, 同时避免使用TreeMap时性能受到的影响。
4)SortedMap接口和TreeMap实现类
类似于SortedSet及TreeSet,TreeMap也可以自定义比较器(Comparable)实现定制排序。它的额外提供的方法也与TreeSet类似,增加了访问第一个、前一个、后一个、最后一个key-value对的方法,并
提供了从TreeMap中提取子集的方法。TreeMap不允许null作为key,要不然怎么比较呢?
5)IdentityHashMap类
与HashMap的不同在于,只有两个key严格相等(key1 == key2)时,IdentityHashMap才认为两个key相等;而对于普通HashMap而言,只要key1.equals(key2)且hashCode相同即可。同样允许null值,不能保证顺序。
6)EnumMap类
EnumMap是一个与枚举类一起使用的Map实现。它的key必须是单个枚举类的枚举值。EnumMap不允许使用null作为key,但可作为value。
3.2、各种map类选择策略
正常情况使用HashMap,而不是Hashtable。
如果考虑排序,那么考虑使用TreeMap。通常TreeMap比HashMap等在插入、删除操作时要慢不少,因为它需要在底层采用红黑树来管理key-value对。
如果考虑插入时的顺序,那么使用LinkedHashMap是个不错的选择。
如果想优化垃圾回收,建议使用WeakHashMap实现类(本文未提及);要求key完全匹配(同一对象),则使用IdentityHashMap;还有枚举类不多说了。
关于null值:Hashtable不允许key为null,也不允许value为null;TreeMap与EnumMap不允许key为null;HashMap及其子类LinkedHashMap,IdentityHashMap允许key为null。